

Google Street View hit Japan
During Novell's Hack Week I started a project I was interested around moonlight, but haven't really done it. I'll revisit it once I got one example running (so, no example runs fine yet).
Recently Google Street View has launched in Japan this Summer, and it caused a lot of flamatory and bashing against Google. Details can be read at GlobalVoicesOnline ([*1] and [*2]). Similar arguments occured in France, England, Canada etc., and the U.S (I think, everywhere).
I'm not to explain all about the arguments, but to just update my recent status. Read those articles above if you are interested.
As one of the board members of MIAU, I was privately busy for preparing a symposium on Google's Street View, to discuss it publicly, for about 60 attendees. (Japanese news links: [*1], [*2] and [*3])
Apart from the organization which stands at neutral position, I keep (blogging about it (in Japanese) mostly raising caution that people should calm down, point problems precisely in precise context and distinguish issues and nonissues for each subject people raised, so that we do not have to shut down any kind of web service deployments unnecessarily. Even standing on such prudent position, it's been very hard to correct those furious people. I am also defamed by a lot of people including Anonymous Cowards in slashdot.jp for posting fair (in my belief) evaluation on those opinions. (Like "If there's risk of some property rights then it should be evaluated in an evenhanded fashion" => "F you")
It's not an easy bug to get resolved.
rejaw
Yesterday friends of mine have released Rejaw, a microblogging-like, Comet-based threaded web chat infrastructure. It is with a full set of API. The introduction can be read here. I was one of the alpha testing users.
There are already some articles introducing Rejaw:
- Rejaw is Not Just Another Twitter Clone (mashable)
- Rejaw: Combining Microblogging + Chat (readwriteweb)
interesting article on how MySpace and Facebook are failing in Japan
This article mostly explains correctly why MySpace and Facebook are not accepted by Japanese.
joining SNS by real name regarded as dangerous
Yes, when Facebook people visited Japan and explained their strategy to expand their market in Japan, by advertising "trusted by real name" network, we found it mostly funky. As the article explained, it is already achieved by mixi. And by that time, mixi is already regarded as dangerous "by exposing real name too widely".
One of the example accidents happened in 2005 August, at the comic market. Comic market place is usually flooded by terrible numbers of otaku people, and they used to be looking bad in general. One of a part time student workers at a hot dog stand wrote an entry in "mixi diary" like: "there was a lot of ugly otaku people there. eek!"
While it is pretty much straightforward, those otaku guys got hurt (at least some of them loudly claimed so), upset and started "profiling" who is that student. It was very easy in mixi, because mixi at that time encouraged to put real-life information with real name. No sooner she was then flooded by a lot of blaming voices, she disappeared from mixi.
OK, she was too careless, or ideally she should not write it (it is always easy to say something ideal). But she was not a geek and does not really understand how the network (mixi) is "open" to others (it is not really "open" by invitation filters, but as mixi grew up to have millions of users, it is of course not "trusted network" anymore). She didn't blame a specific person, and hadn't felt guilty until the company forced her to apologize. This kind of "careless" accidents has kept happening in mixi and it became a social problem.
Nowadays we have the same issue around "zenryaku-prof", where not a few children has faced troubles (for example sexual advances) by the face that the network is "open" to the web by default, while they think it isn't.
Though there must have been similar incidents outside Japan too (for example people fired by his or her blogs), the above (I believe) is the general understanding of the situation in Japan.
Mobile web madness
Another obvious point for Japanese, but would not for else, is that Japanese mobile web support is more important than anything, to get more people joined. Mixi is of course accessible from our cell phones. Even more funky example is "mobage-town", which used to limit access only from cell phones(!). (It is done by sending "contract ID", which is terrible BTW.) Mobage-town is one of the mega hit site in Japanese mobile web. It is mostly for games on the cell phones, but also has a huge SNS inside. It is also funky that the network used to be mostly filled by under-20 children. (Now children grew up to above 20, so the number is not obvious.)
Typically Japanese people spend a lot of boring time, between home and their offices or schools, on trains or buses. They can only do some limited "interesting" stuff. It used to be readings for example, and nowdays it is the mobile web.
Twitter was very successful unlike those failing players. Though I don't think the explanation on the TechCrunch article is right. Twitter had spread by "movatwitter", which is designed as the mobile web UI (and twitter is fully accessible by the API) as well as some additional values such as on-the-fly photo uploader (like Gyazickr for iPhone). It also filled our need (microblogging is a very good way to fill our boring time during our daily move). It lived very well in the mobile web land: no Javascript, no applets, no requirements for huge memory allocation.
When facebook is advertised with its API, what came to my mind was: "Is it even possible to make it for Japanese mobile web? nah"
While we, as a member of "open" world wide web, do not really like this mobile-only web (probably we should read Jonathan Zittrain), it is not a trivial demand that a cell phone is accessible to the mobile-only network. For example, iPhone 3G does not support it (iPhone BTW lacks a lot of features that typical Japanese people expect: for example, camera shake adjuster, it does not provide mobile TV capability, the mobile wallet etc.). It is often referred as "Galapagos network", which is intended as failing to expand their businesses abroad (one of the commentor on the TechCrunch entry mentions it. It is even funny that those iPhone enthusiasts try to claim that their web applications are "open" (as compared to Japanese mobile-only network).
BTW a commentor on the TechCrunch entry tries to object the fact written by the article by quoting google trends worldwide. But (including the graph on top of the article) it is a typical failure on measuring Japanese web access statistics: it does not reflect mobile web access. It is already explained (in Jaanese) very well. The simple fact is that it is becoming less ambient through Alexa, google trends or whatever similar.
SNSes are often domain specific
We would have seen similar phenomena in everywhere else. In China it is QQ. Orkut quickly became SNS for Brazil. There is no universal best.
What other SNSes find business chances in non-mainland countries is some specific purpose. For example, MySpace in Japan is good for producing musicians with its rich UI (many of them would also use mixi as well though).
You Mono/.NET users do NOT use XML, because you don't really know XML
Are you using XML for general string storage? If yes, most of you are likely wrong. If you do not understand why the following XML is wrong and how you can avoid it, do NOT use XML for your purpose.
<xml version="1.0" encoding="utf-8"> <root>I have to escape \u0007 as </root>
If you gave up answering by yourself, read what Daniel Veillard wrote 6 years ago.
System.Json
I read through Scott Guthrie's entry on Silverlight 2.0 beta2 release and noticed that it ships with "Linq to JSON" support. I found it under client SDK. The documentation simply redirects to System.Json namespace page on MSDN.
So, last night I was a bit frustrated and couldn't resist. I'm not sure if MS implementation should work like this yet though.
(You can build it only manually right now; "cd mcs/class/System.Json" and "make PROFILE=net_2_1". The assembly is under mcs/class/lib/net_2_1. You can't do "make PROFILE=net_2_1 install".)
I picked up a sample on another Linq to JSON project to try mine - that is, James Newton-King's JSON.NET. At first, I simply replaced type names and it didn't work. The problematic lines are emphasized below:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Json;
using JsonProperty = System.Collections.Generic.KeyValuePair<
string, System.Json.JsonValue>;
public class Post
{
public string Title;
public string Description;
public string Link;
public List<string> Categories = new List<string> ();
}
public class Test
{
public static void Main ()
{
List<Post> posts = new List<Post> ();
posts.Add (new Post () { Title = "test", Description = "desc",
Link = "urn:foo" });
JsonObject rss =
new JsonObject(
new JsonProperty("channel",
new JsonObject(
new JsonProperty("title", "Atsushi Eno"),
new JsonProperty("link", "http://veritas-vos-liberabit.com"),
new JsonProperty("description", "Atsushi Eno's blog."),
new JsonProperty("item",
new JsonArray(
from p in posts
orderby p.Title
select (JsonValue) new JsonObject(
new JsonProperty("title", p.Title),
new JsonProperty("description", p.Description),
new JsonProperty("link", p.Link),
new JsonProperty("category",
new JsonArray(
from c in p.Categories
select (JsonValue) new JsonPrimitive(c)
))))))));
Console.WriteLine ("{0}", rss);
JsonValue parsed = JsonValue.Parse (rss.ToString ());
Console.WriteLine ("{0}", parsed);
}
}
Unlike Linq to JSON in JSON.NET, JsonObject and JsonArray in System.Json do not accept System.Object as argument. Instead, it requires strictly-typed generic IEnumerable of JsonValue. That is, for example, IEnumerable<JsonPrimitive> is invalid. Thus I was forced to add explicit cast in my linq expression.
It may be improved in SL2 RTM though. Linq to XML classes accept System.Object argument to make it simple (and well, yes, sort of error-prone).
no passionate SOAP supporter in Mono yet
Two years ago I once worked on System.Web.Services complete 2.0 API. That was the worst shamest work I ever had (I hate SOAP). The work was done two years ago, and then there has been no maintainer since the completion. If there is anyone who loves SOAP, he or she can be a hero or heroine.
XIM support on Windows Forms
Recently Jonathan (Pobst) announced that our Winforms became feature complete.
Besides feature completeness, there is another important change in the next mono release. We were not ready for multi byte character input. Since we use X11 for Winforms on Linux, we have to treat multi byte input as special case.
We had some code that handles XIM but that was not for text input support. Since there was no one in the winforms team who lives in multi byte land, we hadn't take care of it.
I was not familiar with those stuff, so it took somewhat long time, but lately I got it practically working. I use scim and Atok X3 (it is one of popular traditional commercial Japanese IM engine), which show different behavior / use of X.
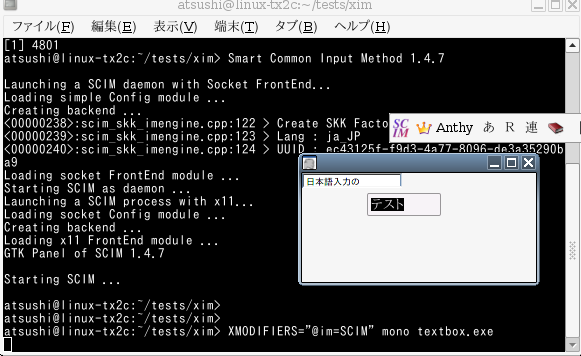
The style is over-the-spot (like .NET) and hence it is not as decent as Gtk (i.e. on-the-spot). Also, it supports only XIM (it would be possible to support better IM frameworks like IIIMF). But for now I'm content with a working international input support.
So if you are living in multi byte land, try the next release or daily build version of mono and feel happy :-)
Linq to DataSet
Since (I thought) I'm done with winforms XIM support, I moved away and started working on System.Data.DataSetExtensions two days ago. Now it's feature complete.
WebHttpBinding - my unexpected Hack Week outcome
Novell had the second "Hack Week". At the beginning I never thought that I was going to implement WebHttpBinding from .NET 3.5 WCF (I was planning to play around some XSLT stuff but soon changed my mind). Actually I have to say, it is not an outcome from just a week - from our patch mail lists I seem to have spent about two weeks. So, I'm cheating ;-)
Anyhow, the Hack Week is over, and now I have partly implemented WebHttpBinding and its family, with a (simple) sample pair of a client and a server that sort of work.
Note that it is (and our WCF classes are) immature and not ready to fly yet.
For details
Want to know the details? Are you serious? OK ... so we have:
- JsonReaderWriterFactory and JSON reader and writer implementations (which supports "__type" as runtime type)
- DataContractJsonSerializer, which is JSON reader/writer-friendly implementation of XmlObjectSerializer
- WebHttpBinding and WebMessageEncodingBindingElement which are to create MessageEncoder that 1) reads stream of JSON or XML into a Message, and/or 2) writes Message into JSON or XML
- UriTemplate and family, which are 1) to retrieve request parameters from its requested HTTP GET URL and/or 2) to generate HTTP GET request URL.
- WebHttpBehavior, which is to provide HTTP GET support by overwriting IClientMessageFormatter and IDispatchMessageFormatter (they are used for example to convert GET URL from and to the parameters for the runtime method (MethodInfo) call.
- QueryStringConverter, which is used to convert request parameter string (retrieved by UriTemplate) to its expected Type.
- WebHttpDispatchOperationSelector, which works as IDispatchOperationSelector and makes use of UriTemplateTable to find out matching a service operation based on the HTTP request.
... and couple of other bits (such as WebChannelFactory or WebServiceHost, which are really cosmetic).
We still don't have couple of things (I am enthusiastic for explaining how we are incomplete :/) :
- configuration support
- JsonQueryStringConverter. It's just not done yet.
- WebScriptEnablingBehavior (and hence ASP.NET AJAX integration)
- WebOperationContext and its helpers. I'm not sure how I can use them (especially when to instantiate IExtension<OperationContext>).
Here I haven't mentioned everything in System.ServiceModel.Syndication namespace, which is already done.
I also have current class status of System.ServiceModel.Web.dll in Olive.
Stopping making copyright law worse than before
Congraturations Canadian Citizens!
We, MIAU, are also fighting right now. We are so busy on preparing for the upcoming symposium which is to be held on 26th.
Syndication API
Wow, I haven't written anything for 6 months. Actually I had been quite busy(?) on several things (namely founding MIAU). In Mono land I had been working on 2.0 API completion those days.
Anyways. At the end of Mono Summit last month, Miguel sorta asked me to hack Syndication API in .NET 3.5, which will be likely part of Silverlight 2.0. So, after some terrible experience in trip back to home (I have lost my buggage on my returning flight, and I had some bad stomachache for more than a week ...), I have started working on it (while I'm having sparse work days and a lot of off days this month). And now, System.ServiceModel.Syndication is almost done.
(... no, you don't have to waste your precious time on learning WCF. You can use the Syndication API almost independently.)
Moved
This blog was moved. Well, only literally, and the same contents still appear, as long as it is blog text. The rental hosting server I used to use, stepserver.jp, had a critical accident that all files entirely vanished. This is the worst shutdown for me and hence let me decide move to other place.
The firefox add-ons that cause performance down
Today I attended to Firefox devcon Summer 2007 Tokyo. There was more than 150 attendees, which was pretty big for such a conference for an application. I heard that even meetings in Mountain View were not like this. Japanese mozilla community certainly seems to be big.
It is nothing to do with the conference above, but this anonymous guy showed an interesting analysis on which Firefox add-ons cause performance down, with three test pages (6 level tables, 7 level tables and JS-CPU bench). It is written in Japanese so most of you wouldn't be able to read it, but the culprit add-ons can be seen as listed in a table in the middle of the page (the table without "ok"). The biggest one was AdBlock Plus. His add-on adjustments resulted in about 4x perf. boost:
- disable Firebug
- replace Linkification with Text Link
- replace IETab with IEView
- replace Google Toolbar with Googlebar Lite
- replace noScript with McAfeeSiteAdvisor or manually configure Javascript
- disable Greasemonkey unless you actually use it. Stylish works more efficiently than AdBlock or user scripts.
According to this guy, (I'm not sure if it is true but) it seems that IPv6 support is said a bad boy, but it is not true. Interesting.
olive XLinq updates
During Japanese holiday week (aka Golden Week), I made significant updates to our XLinq stuff (System.Xml.Linq.dll) in "olive" tree. It has been about 1 year and half since the first checkin, and except for some cosmetic changes it had been kept as is.
It still lacks couple of things such as xsd support and XStreamingElement, but hopefully it became somewhat functional. And from the public API surface by corcompare it is largely done.
Miguel and Marek has been adding some of C# 3.0 support to the compiler, and I heard that there was another hacker who implemented some type inference (var) stuff, so at some stage we will see Linq to XML in action (either in reality or in test tube).
Other than that I did almost nothing this holiday week, except for spending time on junk talk with Lingr fellows. The worst concern about lingr (which is agreed among us, including one of the four lingr dev. people) is lowering productivity due to too much fun talking with them, especially when it is combined with twitter, which is somehow becoming bigger in Japan ...
Speaking of twitter, I was asked some mono questions (mostly about bugs) by a Japanese hacker and ended up to know that he wrote TwitterIrcGateway and was trying to run it with mono. It is a WinForms application (for task tray control) which requires some soon-to-be-released v1.2.4 features but it just worked out of the box on my machine. It is so useful.
Bugs and standard conformance, when it comes from MS
My recent secondary concern is about the lack of legal mind and English-only nationalism in American House of Representatives on "Ianfu" issue, as well as the concern on Nanking massacre denialists's attack on the film 'Nanking'. But both are political topics that I usually don't dig in depth...
My recent primary concern is about the essential private rights in Japanese private law system, which seems correctly imported from German pandecten and incorrectly adopted to Japanese law. My recent reading Japanese book "the distance between freedom and privilege", which is based on Carl Schmidt and talks about the nature of limitation on (property) rights, was also nice. I'm hoping that those arguments would decrease some basic misunderstandings on the scope of copyrights in principle.
Anyways.
As some of mono community dudes know, I always fight against those who only consider .NET compatibility than conformance to standards. They end up to try to justify date function to be incorrect even in the proposal draft of standards just because of a bug in MS Excel (as well as Lotus), which doesn't really make sense.
Anyways what I remembered on seeing Miguel's doubt on MS compiler (csc.exe) behavior was my own feedback to MS that csc has ECMA 334 violation on comparison between System.IntPtr and null (I believe System.IntPtr.Zero is introduced exactly for this issue). I reported it about one year ago when I was trying to build YaneSDK.NET (an OpenGL-based game SDK) on mono.
This bug had left until Jan 31, and then it was closed without any comments. I quickly reopened it and thus it is still active. Of course I totally don't mind that .NET has bugs (having live / long-standing issues is very usual) including ECMA violations.
Since I have reported couple of .NET bugs, sometimes I saw "interesting" reactions. In this case, MS says that this is "a bug in ECMA spec" so that "they will come up with a new spec". They think they "own" the control of the specification (I'm not talking about the ownership of the copyrights on the specification).
After all, it seems that I'm always concerned about rules and justifications.
Kind of back
Looks like six months have passed since my last entry. I was not dead at least literally. Lately my interest has been on some legal stuff (especially criminal law) which is of course in Japanese context. Anyways ...
So, I have been working on WCF implementation now. The Olive plan was announced back in October, but the work was started much earlier, like in Autumn 2005. Though as you would guess, it has been flaky - I haven't chosen WCF over helping Winforms last spring, or over ASP.NET 2.0 Web Services last winter (and it's still ongoing).
BasicHttpBinding was already working last spring, and ClientBase was working last summer. Ankit had been working on WSDL support and ASP.NET .svc handler, until we decided some work reassignment during the Mono Meeting days in October. (He is now working on MonoDevelop - am so envious! ;-) MonoDevelop hacking is a lot of joy than WS-* sack.)
After making ClientBase working, my primary task in this area has been to get WS-Security (SecurityBindingElement) working. WS-Security and WS-SecurityPolicy are nightmare. There is a lot of work in this area. I dug several security classes in depth to make my sample code simpler, simpler and simpler. Now I have very primitive pair of service and client. And after several bugfixes primarily in System.ServiceModel.dll and System.Security.dll, finally I got my WS-Security enabled message successfully consumed by WCF :-)
Probably none of you would understand why I am so excited about it since the code still is not practically working yet, but I am happy right now. I would need a lot more words to explain why, and I doubt it is worthy :|
Microsoft Permissive License
As I often write here, the worst legal violation I dislike is False Advertising.
Did you ever know that there are more than just one Microsoft Permissive License? I only knew this one which is widely argued that it could be regarded as conformant to Open Source Definition.
I originally disliked the idea that this MS-PL labelled as one of that "Shared Source License", as it rather seemed an attempt to justifying existing restricted shared source licenses, while I like that MS-PL terms in general.
Now, read this Microsoft Permissive License. It is defined as:
(B) Platform Limitation- The licenses granted in sections 2(A) & 2(B) extend only to the software or derivative works that you create that run on a Microsoft Windows operating system product.
This is an excerpt from Shared Source Initiative Frequently Asked Questions:
Q. What licenses are used for Shared Source releases?A. [...] Microsoft is making it easier for developers all over the world to get its source code under licenses that are simple, predictable, and easy to understand. Microsoft has drafted three primary licenses for all Shared Source releases: the Microsoft Permissive License (Ms-PL), the Microsoft Community License (Ms-CL), and the Microsoft Reference License (Ms-RL). Each is designed to meet a specific set of developer, customer, or business requirements. To learn more about the licenses, please review the Shared Source Licenses overview.
(Emphasis by myself.)
Now I wonder if this is the exact reason why Microsoft did not submit MS-PL as Open Source Definition conformant license.
Now I ponder the legal affection on this behavior (as I was a law student). If it is not regarded as illegal false advertising, it would result that any kind of license statements lose reliability. If it is regarded as illegal, it would result that any kind of authors are imposed to keep their licenses every time they modified. Oh, maybe not all. It could be just limited to wherever SOX laws apply. Which is better?
CCHits
Recently I got to know CCHits, a digg-like music ranking website specialized to which are available in Creative Commons license (as a normal ex law student I am a big fan of CC). This is what I really wanted to see or build. Since I just moved to my new room and am without fast connection I cannot practically use it right now, but I really want to try it asap. Music is one of the things that I dream to be free, like cooking recipe where no rights lie and there are still improvements. There is a lot of boring commercial songs that are still used just to make some sounds in shops and waste money.
Now what lacks there is the ranking counts. I'd like to see at least hundreds of votes. When I'm ready, I'd start from listening high-rated songs and add more hits to make this website grown up enough like digg.
There are some great search engines to help finding CC musics: Yahoo! and Google. I love those search engines, not because they are innovative, but because they recognizes how freedom represented as CC is important. There are some other search engines which are rather interested in their own "innovation", but is not something that I am interested.
It also reminded me of what Microsoft people said about Google Spreadsheets. I think such argument that "Google Spreadsheets is not innovative because it is what google acquired" is really ignorable. That made me feel that Microsoft altitude is 10 years behind Google. I am rather interested in the company principle behind (say) Google Book Search.
OpenDocument validator
Someone in the OpenDocument Fellowship read my blog entry on RelaxngValidatingReader and OpenDocument, and then asked me if I can create example code. Sure :-) Here is my tiny "odfvalidate" that validates .odt or its content xml files (any of content.xml, styles.xml, meta.xml, or settings.xml should be fine) using the RELAX NG schema.
I put an example file to validate, actually simply converted OpenDocument specification document by OO.o 2.0. When you validate the document, it will report you a validation error which is really an error in content.xml.
Mono users just can get that simple .cs file and OpenDocument rng schema, and then compile it as "mcs -r:Commons.Xml.Relaxng -r:ICSharpCode.SharpZipLib". Microsoft.NET users can still try it, by downloading those dll files listed there.
Beyond my tiny tool, I think AODL would be able to use it. In the above directory I put a tiny diff file for AODL code. Add Commons.Xml.Relaxng.dll as a reference, add OpenDocument-schema-v1.0-os.rng as a resource and then build. I haven't actually run it so it might not work though.
If any further questions, please feel free to ask me.
We need WinForms bugfixes
Lately I was mostly spending my time on bugfixing core libraries such as corlib and System.dll. Yesterday I got to know that we need a lot of bugfixes in our MWF (managed win forms).
So I have started to look around existing bug list and work on it. At first I thought that it is highly difficult task: to extract simple reproducible code from problematic sources, and of course, to fix bugs. Turned out that it is not that difficult.
Actually, it is very easy to find MWF bugs. If you run your MWF program, it will immediately show you some problems. What I don't want you to do at this stage is just to report it as is. We kinda know that your code does not work on Mono. It's almost not a bug report. Please try to create good bug report. Here I want to share my ideas on how you can try creating good MWF bug reports and bugfixes.
(Dis)claimer: I'm far from Windows.Forms fanboy. Don't hit me.
the background
Mono's Windows Forms implementation is WndProc based, which is implemented on top of XplatUI framework. For drawing we have Theme engine which is implemented on top of System.Drawing which uses libgdiplus on non-Windows and simply GDI+ on Windows.
Thanks to this architecture, if you have both Windows and Linux (and OSX) boxes, you can try them and see if all of them fail or not. In general we have XplatUI implementation and Theme implementation for each environment (XplatUIWin32, XplatUIX11, XplatUIOSX and ThemeClearLooks, ThemeGtk, ThemeNice, ThemeWin32Classic), so the bug you are tring to dig might be bugs in there (well, also note that if you have wrong code such as Windows-path dependent code, it won't work. Here I continue winforms-related topic). To find out the culprit layer:
- If only non-Windows box fail, then it might be bugs in libgdiplus or Cairo as its background. If Only OSX fail, then it is likely to be some architecture (big endian etc.) related bug.
- Otherwise it is likely to be misimplementation of our class libraries including MWF controls. System.ComponentModel and System.*Design classes are also likely to be culprit.
See our WinForms page for more backgrounds.
find the culprit
The first stage is to find out the problematic component.
- We fix several bugs everyday. So always try the latest mono, mcs and libgdiplus from svn. Trying MWF on stable releases (1.1.13.x) is almost helpless. The code is rapidly improved by the MWF team.
- Compile your code with -debug option. It will result in more informative stack trace (file and line).
- Check existing bugs. When you hit a problem, there would be the same or similar problem.
- Reproducible bugs are much better than non-reproducible bugs. Try to find a consistent way to reproduce the bug. On bug report, having the procedure is much more helpful. It is also nice if you can provide reproducible steps for existing bug reports that do not have repro steps.
- Try simpler controls for whatever you found bugs as well. For example, if ComboBox focus does not work, there is likely another bug on focus handling.
- sometimes trying indifferent controls also helps. It might not be a bug in the exact control you are touching, but might be a bug in the container, MDI, Form or drawing in general.
create a simple repro code
Once you think you found the culprit control, try to create a simpler reproducible code. It does not only help debugging (those bugs without "readable" code are not likely be fixed soon), but also avoids your mistaken assumption on bugs.
When you try to create simple repro code, you can reuse existing simple code collection.
If you are not accustomed to non-VS.NET coding, Here is my example code:
using System;
using System.Windows.Forms;
public class Test : Form
{
public static void Main ()
{
Application.Run (new Test ());
}
public Test ()
{
#region You can just replace here.
ComboBox cb = new ComboBox ();
cb.DropDownStyle = ComboBoxStyle.DropDownList;
cb.DataSource = new string [] {"A", "B1", "B2",
"C", "D", "D", "Z", "T1", "B3", "\u3042\u3044"};
Controls.Add (cb);
#region
}
}
Compile it with mcs -pkg:dotnet blah.cs.
bugfixing
After you create good bug reports (also note that we have a general explanation on it), it wouldn't be that difficult to even fix the bug :-) Actually we receive a lot of bug reports, while we have relatively few bugfixors.
As Ximian used to be GNOME company, external skilled Windows developers would know much better on how to implement MWF controls and fix bugs. In my case I even had to start bugfixing from learning what kind of WindowStyles there are (WS_POPUP etc. that we define in XplatUIStructs.cs).
My way of debugging won't be informative... Anyways. When I try to fix those MWF bugs, I just use a text editor and mono --trace. My frequently used option is --trace=T:System.Windows.Forms.blahControl. I mostly spend time on understanding the component I'm touching.
When you created a patch (hooray!), adding [PATCH] prefix on the bug summary would be nicer so that we can find possible fixes sooner.
Another NVDL implementation
Lately Makoto Murata told me that another NVDL implementation appeared. I am extraordinary pleased. Before that there was only my NVDL implementation, which means that NVDL has not been worthy of the name of a "standard".
It is also awesome that this implementation is written in Java, which means that it has different fields of users. Now I wonder, when will C implementation be there? :-)
BTW Makoto Murata also gave me his NVDL tests which is in preparation and I ended up to make several updates on my implementation. Some tests makes me feel something like "uh? Is NVDL such a specification?" i.e. I had some misunderstanding on the specification. With it I could also update a few parts to the FDIS specification (I wrote my implementation when it was FCD). As far as I know the tests will be released under a certain open source license (unlike BumbleBee XQuery test collection).
the Mono meeting in Tokyo
We have finished the latest Mono meeting in Tokyo targetting Japanese, with Alex Schonfeld of popjisyo.com. (we call it "the first meeting" in Japanese but as you know we used to have some non-Japanese ones.)
At the time we announced it [1] [2] I personally expected 5 or 6 people at best so that we can make somewhat in-depth discussion about Mono, depending on the attendees. What happened was pretty different. We ended up to welcome 16 external attendees (including akiramei), so we rented the entire room in the bar and mostly spent time from our presentations and Q & A between them and me. We were so surprised that such tiny pair of announcements were read by so many people.
It was a big fun - there was an academic guy who writes his own C#/VB compilers referencing mcs/gmcs. There was a guy who wants to know some details about JIT. I also met a person who was trying my NVDL validator. There was a number of people who are interested in running their applications under Mono (well, Alex has also long been interested in ASP.NET 2.0 support). Many guys were interested in how Mono is used in production land. There were also many guys claiming that Mono needs easiler debugging environment. Some people are interested in how Mono is ready for commercial support.
As usual I have some regressions on the progress but the meeting went so well. It is very likely that we plan another Japanese Mono meeting.
opt. week
Happy new year (maybe in Chinese context).
About a week and more ago Miguel told me that there is summary page for performance comparison for Java, Mono and .NET by Jeswin.P.
It is always nice to see that someone is kind enough to provide such information :-) The numbers however are not good for Mono, so I kinda started attempt to enhance mono XML performance.
Miguel told me that I can't know how those performance improvement record is impressive to some users (well, I totally agree; I was not surprised to see the perf. results). So I started to record that XMLmark results, now using NPlot (for Gtk# (0.99)). You can see sort-of-daily graph, like:


As you see, this measuring box has some errors, but it won't matter so much. Anyways, not bad. The most effective patch was from Paolo.
The next item I want(ed) to optimize was Encoding. I have already done some tiny sort of optimization in UTF8Encoding (the latest svn should be about 1.2x-1.3x faster than 1.1.13), but it needs more love. It is ongoing.
The best improvements I have made was not any of the above. I had been optimizing my RelaxngValidatingReader by feeding OpenDocument grammar which is about 530 KB and some documents (I extracted it and converted to .odt using OO.o 2.0 and extracted content.xml).
At first I couldn't start from that massive schema. I had to fix several bugs. I spent most of hacking time on it last winter vacations. It became pretty solid. Those new year days I started to validate some OpenDocument content.
I started from one random pickup of OASIS docs, maybe this one, which was about 70KB, 1750 lines of instance. At svn r54896 it almost stopped around line 30: too bad start. I started to read James Clark's derivative algorithm again, and started several attempt to optimize it. After some step-by-step improvements, at r55497 the validator finally reached to the end for the first time. I still needed further optimization since it cost me about 80 seconds, but one hour later it went nearly 20x faster, at r55498.
After having 70KB document validated within 5 seconds, I thought it was time to try the biggest one - OpenDocument 1.0 specification. I added indentation to this 4MB of content.xml and it became 5MB. After fixing XML Schema datatype bug that was found at line 4626, I had to make further optimization, since it was eating up the memory, looked almost infinite. I dumped the list of total memory consumption for each Read(), but the fix (r56434) was stupidly simple. Anyways finally I could validate 5MB of an instance in 6 seconds.
So, now it is possible enough to validate OpenDocument xml using RelaxngValidatingReader, for example with AODL, An OpenDocument Library.
Maybe it's time to fix remaining 8 bugs found by James Clark's test suite - 7 are from XLink 5.4 violation, and 1 is in unique name analysis.
(sorry but no plot for RELAX NG stuff, it is kind of non-drawable line ;-)
Lame solution, better solution
During my in-camera vacation work, I ended up to fix some annoying bugs in Commons.Xml.Relaxng.dll. Well, they were not that annoying. I just needed to revisit section 4.* and 7.* of the specification. Thanks to my own God, I was pretty productive yesterday to dispose most of them. After r54882 in our svn, the implementation became pretty better. Now I have 13 out of 373 testcases from James Clark's test suite. Half of them are XLink URI matter and most of the remaining bits are related to empty list processing (<list><empty></list>, which usually is not likely to happen).
Speaking of Commons.Xml.Relaxng.dll, I updated my (oh yeah here I can use "the" instead of "my" for now) NVDL implementation to match the latest Final Draft International Standard (FDIS). The specification looks fairly stable and there were little changes.
MURATA Makoto explains how you can avoid silly processor-dependent technology (not) to validate xml:*, such as System.Xml.Schema.XmlSchemaValidationFlags. Oh, well you don't have to worry about that there is no validator for Java - someone in rng-users ML wrote that his group is going to implement one. It would be even nicer if someone provide another implementation for libxml (it won't make sense if I implement some).
I hope I have enough time to revisit this holiday project (yeah it is mostly done in my weekends and holidays) rather than wasting my time on other silly stuff.
Holy shit
Wow, I haven't been blogged for a while. It just tells that I have done nothing that long. And am going to hibernate this year (having summer vacations next two weeks).
I wanted to get somewhat useful schema before writing some code for Monodoc. After getting lengthy xsd, I decided to write dtd2rng based on dtd2xsd (this silly design is because I cannot make Commons.Xml.Relaxng as System.Xml dependency) and got a smart boy. (Well, to just get converted grammar like this, you could use trang).
We are going to have Mono meeting in Tokyo next Monday. The details are not set yet, but if any of you are interested, please feel free to ask me the details. (it is likely to be just having dinner and drinking, heh).
Last month I went to Kyoto (Japan) with Dan (Mills, aka thunder) and found a nice holy shit:

Unfortunately, I lost this religious treasure last week :-( I was pretty disappointed. It must be from I entered a Starbucks to I got on a train (I noticed that I lost it at that time). So I was wondering if I should ask those Starbucks partners like "didn't you guys see my shit here?" All my friends whom I asked for advice were saying I should do, so I ended up asking the partners.
"I might lost my cell accessory here."
"What colour was it?"
"Well, it was a golden cra..."
"Ok, please wait for a while"
... and then she went into staff room, and said there was no such one. After a few seconds of wondering if I should be more descriptive, but was reminded. Shame.
don't use DateTime.Parse(). DateTime.ParseExact() instead
It seems that very few people know that DateTime.Parse() is COM dependent, evil one. Since we don't support COM, those COM dependent functionality won't work fine on Mono.
Moreover, even in Microsoft.NET, there is no assurance that such string that DateTime.Parse() accepts on your machine is acceptable under other machines. Basically DateTime.Parse() is for newbies who don't mind unpredictable behavior.
Yes,
instead of
is quite annoying because of its lengthy parameters. If you think so, you can push Microsoft to provide an equivalent shortcut, like I did. But first thing you should do right now is to prepare your own MyDateTime.Parse() that just returns the same result of the above. It's also true to several culture-dependent String methods (IndexOf, LastIndexOf, Compare, StartsWith, EndsWith - all of them are culture sensitive, even with InvariantCulture) to avoid unexpected matches/comparisons (remember that "eno" and "eno\u3007" are regarded as equivalent).
Default encoding for mcs
Today I checked in a patch for mcs that changes the default encoding of the source file, to System.Text.Encoding.Default instead of Latin1. Surprisingly we have been using it as the default encoding, regardless of the actual environment. For example, Microsoft csc uses Shift_JIS on my Japanese box, not Latin1 (Latin1 is even not listed as candidate when we - Japanese - save files in text editors).
This change brought confusion, since we have several Latin1-dependent source files in our own class libraries, and on modern Linux environment the default encoding is likely to be UTF8, regardless of the region and the language (while I was making this change on Windows machine). Thus I ended up to add /codepage:28591 to some classlib Makefiles at first, and then to revert that change and started a discussion.
I felt kinda depressed, on the other hand I thought it's kinda interesting. I must be making such a change that makes sense, but it is likely to bring confusion to EuroAmerican people. Yes, that is what we (non-EuroAmericans) had experienced - we could not compile sources and used to wonder why mcs can't, until we tried to use e.g. /codepage:932. When I went to Japanese Novell customer to help deploying ASP.NET application on SuSE server, I had to ask them to convert the source to UTF-8 (well now I think I could ask to set fileEncoding in web.config instead, but anyways not sure whether CP932 encoding worked fine or not).
If mcs does not premise Latin1, your Latin1-dependent ASP.NET applications won't run fine in the future version of mono on Linux. Even though mcs compiled sources with the platform-dependent default encoding instead of Latin1, it does not mean that your ASP.NET applications written in your "native" encoding (on Windows) will run fine on Linux without modifications. As I wrote above, the default encoding is likely to be UTF8 and thus you will have to explicitly specify "fileEncoding" in your web.config file.
Sounds pretty bad? Yeah, might be for Latin1 people. However, it has been happening on non-Latin1 environment. Thus almost no one is likely to be saved. But going back to "Latin1 by default" does not sound a good idea. At least it is not a culture-neutral decision.
There is a similar but totally different problem on DllImportAttribute.CharSet when the value is CharSet.Ansi. It is locale dependent encoding on Microsoft.NET, but in mono it is always UTF-8. The situation is similar, but here we use platform-neutral UTF-8 (well, I know that UTF-8 itself is still not culture-neutral, as it definitely prefer Latin over CJK. It lays Latin letters out in 2 byte areas, while most of CJK letters are in 3 byte areas, including only about 200 letters of Hiragana/Katakanas).
Managed collation support in Mono
Finally I checked in managed collation (CompareInfo) implementation in mono. It was about four months task, while I mostly spent my time just to find out how Windows collation table is composed. If Windows is conformant to Unicode standards (UTS #10, Unicode Collation Algorithm, and more importantly Unicode Character Database), it would have been much shorter (maybe in two months or so).
Even that I spent extra months, it resulted in a small good side effect - We got the Fact about Windows collation, which had been said good but in fact turned out not that good.
The worst concern now I have about .NET API is that CompareInfo is used EVERYWHERE we use corlib API such as String.IndexOf(), String.StartsWith(), ArrayList.Sort() etc. etc... They cause unexpected behavior on your application code which does not always have to be culture sensitive. We want them only under certain situations.
Anyways, now managed collation is checked in, though right now it's not activated unless you explicitly set environment variable. The implementation is almost close to Windows I believe. I started from SortKey binary data structures actually that was described in the book "Developing International Software, Second Edition"), sorting out how invariant GetSortKey() returns computed sort keys for each characters to find out how characters are categorized and how they can be drawn from Unicode Character Database (UCD). Now I know most of the composition of the sortkey table, which also uncovered that Windows sorting is not always based on UCD.
From Unicode Normalization (UTR #15) experience (actually it was the first attempt for my collation implementation to implement UTR #15, since I believed that Windows collation must have been conformant to Unicode standard), I made quick codepoint comparison optimization in Compare(), which made Compare() for the equivalent string 125x faster (in other words it was so slow). It became closer to MS.NET CompareInfo but still far behind ICU4C 3.4 (it is about 2x quicker). I'm pretty sure that it could be faster if I can spend more memory, but it is corlib where we should mind memory usage.
I tried some performance testing. Note that they are just some cases and collation performance is heavily dependent on the target strings. Anyways the results were like below and the code are here. (The numbers are seconds):
CORRECTION: I removed "Ordinal" comparison which was actually nothing to do with ICU. It was mono's internal (pretty straightforward) comparison icall.
| Options | w/ ICU4C 2.8 | w/ ICU4C 3.4 | Managed |
|---|---|---|---|
| None | 0.671 | 0.391 | 0.741 |
| StringSort | 0.671 | 0.390 | 0.731 |
| IgnoreCase | 0.681 | 0.391 | 0.731 |
| IgnoreSymbols | 0.671 | 0.410 | 0.741 |
| IgnoreKanaType | 0.671 | 0.381 | 0.741 |
MS.NET is about 1.2x faster than ICU 2.8 (i.e. it is also much slower than ICU 3.4). Compared to ICU 3.4, it is much slower, but Compare() looks not so bad.
On the other hand, below are Index search related methods (I used IgnoreNonSpace here. The numbers are seconds again):
UPDATED: after some hacking, I could reduce the execution time by 3/4.
| Operation | w/ ICU4C 2.8 | w/ ICU4C 3.4 | Managed |
|---|---|---|---|
| IsPrefix | 1.171 | 0.230 | 0.231 |
| IsSuffix | 0 | 0 | 0 |
| IndexOf (1) | 0.08 | 0.08 | |
| IndexOf (2) | 0.08 | 0.08 | |
| LastIndexOf (1) | 0.992 | 0.991 | |
| LastIndexOf (2) | 0.170 | 0.161 |
Sadly index search stuff looks pretty slower for now. Well, actually it depends on the compared strings (for example, changing strings in IsSuffix() resulted in that managed collation is the fastest. The example code is practically not runnable under MS.NET which is extremely slow). One remaining optimization that immediately come up to my mind is IndexOf(), where none of known algorithms such as BM or KMP are taken... They might not be so straightforward for culture-sensitive search. It would be interesting to find out how (or whether) optimizations could be done here.
the "true" Checklists: XML Performance
While I knew that there are some documents named "Patterns and Practices" from Microsoft, I didn't know that there is a section for XML Performance. Sadly, I was scarcely satisfied by that document. The checklist is so insufficient, and some of them are missing the points (and some are even worse for performance). So here I put the "true" checklists to save misinformed .NET XML developers.
- Design Considerations
- Avoid XML as long as possible.
- Avoid processing large documents.
- Avoid validation. XmlValidatingReader is 2-3x slower than XmlTextReader.
- Avoid DTD, especially IDs and entity references.
- Use streaming interfaces such as XmlReader or SAXdotnet.
- Consider hard-coded processing, including validation.
- Shorten node name length.
- Consider sharing NameTable, but only when names are likely to be really common. With more and more irrelevant names, it becomes slower and slower.
- Parsing XML
- Use XmlTextReader and avoid validating readers.
- When node is required, consider using XmlDocument.ReadNode(), not the entire Load().
- Set null for XmlResolver property on some XmlReaders to avoid access to external resources.
- Make full use of MoveToContent() and Skip(). They avoids extraneous name creation. However, it becomes almost nothing when you use XmlValidatingReader.
- Avoid accessing Value for Text/CDATA nodes as long as possible.
- Validating XML
- Avoid extraneous validation.
- Consider caching schemas.
- Avoid identity constraint usage. Not only because it stores key/fields for the entire document, but also because the keys are boxed.
- Avoid extraneous strong typing. It results in XmlSchemaDatatype.ParseValue(). It could also result in avoiding access to Value string.
- Writing XML
- Write output directly as long as possible.
- To save documents, XmlTextWriter without indentation is better than TextWriter/Stream/file output (all indented) except for human reading.
- DOM Processing
- Avoid InnerXml. It internally creates XmlTextReader/XmlTextWriter. InnerText is fine.
- Avoid PreviousSibling. XmlDocument is very inefficient for backward traverse.
- Append nodes as soon as possible. Adding a big subtree results in longer extraneous run to check ID attributes.
- Prefer FirstChild/NextSibling and avoid to access ChildNodes. It creates XmlNodeList which is initially not instantiated.
- XPath Processing
- Consider to use XPathDocument but only when you need the entire document. With XmlDocument you can use ReadNode() but no equivalent for XPathDocument.
- Avoid preceding-sibling and preceding axes queries, especially over XmlDocument. They would result in sorting, and for XmlDocument they need access to PreviousSibling.
- Avoid // (descendant). The returned nodes are mostly likely to be irrelevant.
- Avoid position(), last() and positional predicates (especially things like foo[last()-1]).
- Compile XPath string to XPathExpression and reuse it for frequent query.
- Don't run XPath query frequently. It is costy since it always have to Clone() XPathNavigators.
- XSLT Processing
- Reuse (cache) XslTransform objects.
- Avoid key() in XSLT. They can return all kind of nodes that prevents node-type based optimization.
- Avoid document() especially with nonstatic argument.
- Pull style (e.g. xsl:for-each) is usually better than template match.
- Minimize output size. More importantly, minimize input.
What I felt funky was that they said that users should use XmlValidatingReader. With that they can never say that XmlReader is better than SAX on performance, since it creates value strings for every node (so the performance tips are mutually exclusive). It is not evitable even if you call Skip() or MoveToContent(), since skipping validation on skipped nodes is not allowed (actually in .NET 1.0 Microsoft developers did that and it caused bugs in XmlValidatingReader).
DTLL 0.4
Jeni Tennison told me (well, some guys including me) that she put a refresh version of Datatype Library Language (DTLL), which is expected to be ISO DSDL part 5.
Since Mono already has validators for RELAX NG with custom datatype support and NVDL, there would be no wonder if I was trying to implement DTLL support.
The true history was earlier, but it was the last spring that I practically started to write code for DTLL version 0.3. After hacking on the grammar object model, I asked Jeni Tennison for some examples, and she was kind enough to give me a decent one (the latest specification now includes even nicer examples). With that I have finished the grammar object model.
The next was of course, compilation to be ready for validation. But at that stage I was rather ambicious to support automatic CLI type mapping from DTLL datatype. I thought it was possible, but I noticed that DTLL model was kinda non-deterministic ... that is, with that version of DTLL I had to implement some kind of backtracking of already-mapped part of data if the input raw string did not match in a certain choice branch. With some questions (such as why "enumeration" needs indirect designation by XPath), I asked her about the possibility of limitation of the flexibility of item-pattern syntax. In DTLL version 0.3, the definition of "list" was:
... and today I was reading the latest DTLL 0.4, I noticed that:
... so, the entire item-pattern went away (!). I was surprised at her decision, but I'd say, it is nice. List became just a list of strings... I wonder if it really cannot be typed pattern (I might be shooting my foot now). The specification also removed "enumeration", so the pattern syntax became pretty simple. This change means that almost all patterns are treated as regular expressions. I wonder if it is me to blame ;-)
Now I don't think it is possible to automatically generate "DTLL datatype to native CLI type" conversion code, but I think that such conversion code should be provided from DTLL users. So it seems time for me to restart hacking on it...
cyber crime / axml:id
Lately I was researching about trademarks (many Mono hackers know well about what I am talking here). Sadly, it was much deeper than I have expected. Trademarks are just like a tip on an iceberg. So I got contact with Japanese police and told all the facts I got. I want to believe they can handle the case nicely.
Japanese police is nervous on phishing websites. It was not by chance that I found that, since I was researching about trademarks and the system of Japanese trademark (law and the operation of it) is somewhat related to how to acquire phishable(?) domains legally. It's a bit interesting to learn about those buggy legal systems. Maybe I had better start creating patches to fix those bugs, but the bugs are somewhat complicated.
As the first stage, if any of you guys have received such mails from Japanese saying that you should buy the domains and/or trademarks, or you cannot make business advance into Japan, you can get contact with me. I would help your research on whether he or she really have such valid trademarks or not, though you should really ask Japanese lawyers if I said that the applicant does not or cannot own it. Sometimes Japanese agents are idiots so that they cannot even make appropriate research that I can make.
I noticed that xml:id Proposed Recommendation is out. I found that it states that xml:id is incompatible with Canonical XML in Appendices C.
Lately I rarely touch XML stuff so I had few ideas, but it came up to mind that if xml:id were assigned another namespace URI than http://www.w3.org/XML/1998/namespace, the problem would go away. But anyways now that we have exc-c14n, it's a tiny problem.
Also, I don't think .NET developers should worry about that. When someone implemented xml:id and noticed that it is incompatible with Canonical XML, then he or she would ask Microsoft to change their implementation not to mess it, like Microsoft developers lately had to make changes about validation on xml:* attributes. The problem and the solution are so easy. They would welcome such pollusion if it benefits them.
I don't like opt-out messages
Recently I often look back the last productive year. After Mono 1.0 release I have mostly done System.Xml 2.0 bits (editable XPathNavigator, XmlSchemaInference, XmlSchemaValidator, XmlReader.Create() and half-baked XQuery engine ... none of them rock though. I remember I once started to improve DataSet bits (DataView and related things), but now I don't work on them. Maybe something happened this year and I have done nothing wrt xml bits (well, except for NvdlValidatingReader). Maybe I need something interesting there.
...Anyways, here is the final chapter of Train of RantSort.
Train of Sort #5 - Is UCD (not UCA) used? -
I have wondered if Windows collator uses Unicode Character Database, the core of Unicode specification.
Windows treats U+00C6 (Latin small letter AE; Latin smal ligature AE) as equivalent to "ae". There is a character | U+01E3 (http://www.fileformat.info/info/unicode/char/01E3/index.htm) aka Latin small letter AE with Macron whose Normalization Form Decomposition (NFD) is U+00E6 U+0304 where U+0304 is Combining Macron.
So it looks like we can expect that Compare("\u01E3", "\u00E6\u0304") returns 0. However they are treated as different. Windows treats U+01E3 as equivalent to the sequence 'a' 'U+0304' 'e' 'U+0304'.
Similarly, circled CJK compatibility characters are not always related to ("related" actually means nothing but close primary weight though) non-circled one. For example U+32A2 (whose NFKD value is circled U+5199) is sorted next to U+5BEB (traditional Chinese) instead of U+5199 (Japanese and possibly simplified Chinese).
Those facts do not look like because Windows works differently than UCA. And since this NFD mapping comes from Unicode 1.1 that is released in 1993 (earlier than Windows 95) so they also do not look like because of the time lag. I wonder why those differences happen.
In fact recently I wrote about those CJK stuff to Michael Kaplan's blog entry and thanks to his courtesy I got some answers. That sadly seems irrelevant to the problem above, but he had an enlighting point - NFKD often breaks significant bits. I guess he is right (since some NFKD mappings contain hyphens which is treated specially), but I also think it depends on the implementation (am not clear about such cases at this stage).
It reminded me of some kind of contractions - when I read some materials on Hungarian sorting, I tried comparing "Z", "zs", "zzs" and so on. And on seeing sortkeys, I eventually found that "zszs" and "zzs" are regarded as equivalent on .NET. But I still don't know if it is incorrect or not (even after seeing J2SE 1.5 didn't regard them as equivalent). I doubt they are kinda source of destructive operations, but not sure.
... that's all for now (I feel sorry that there is no "conclusion" here). Windows Collation things are still in the black box, and for some serious development we certainly need explicit design to predict what would happen with collations.
Ok, time to hibernate. My writing battery is going to run out.
Train of Sort #4 - sortkey table optimization
With related to sortkey table and logical surface of collation, I think UCA handles things much better than Windows. Well, I didn't like "logical order exceptions" in UCA, but it disappeared in the latest specification.
For "shifted" characters such as hyphens and apostrophe characters, GetSortKey() considers those characters only at the identical weight. In that case, only primary weight is computed as the actual sortkey value (like 01 01 01 01 80 07 06 80 for ASCII Apostrophe where only 06 80 represent that character). BTW there are such pairs of two characters that differ only in thirtiary weight (width sensitivity lies there) such as U+0027 and U+FF07 (full-width Apostrophe). Those sortkeys are regarded as equivalent when StringSort is not specified as CompareOptions flags (it does not happen when you use Compare()).
Windows has no concept of (non-)blocking diacritical marks. Windows just adds diacritical weight of nonspacing characters to that weight of previous primary character. And since the weight does not handle value more than 255, it often overflows and goes back to 0 (BTW the value 0 indicates the end of the sortkey in Windows API). Moreover, the fact means that there could be several pairs of sequences of diacritical marks that are incorrectly treated as equivalent. I recently mentioned one of such case in mono-devel-list.
Windows collation table is not internally optimizable. For example, (1)Hangul Syllables are sorted, being mixed with Jamo. In UCA it is implemented to be optimizable, but on Windows L/V/T forms are mixed depending on character equivalence and no blank values between them, so the large Hangul Syllable block could not be computed but must just be filled in a bulky table. In UCA and CLDR there is "optimize" option to take. Another example is (2)CJK compatibility characters. Those "compatibility" characters can, however, never be compatible with any of CompareOptions flags. Instead they are sorted next to the "compatible" character. However, if there is no such design, the sortkey table could be impressively optimized since the large chunk of CJK ideograph characters could be computed from their codepoints. I think they could be differentiated only in the third weight area (where width and case insensitivity coexist), or the fourth weight area (as well as Japanese Kana, since anyways those characters differ in primary level).
CJK sortkeys and CJK exntension sortkeys are immediately joined. On Windows, CJK ideograph ends at U+9FA5. In the latest Unicode the last CJK ideograph character is U+9FBB. But there is no proper space for U+9FA6-U+9FBB in Windows sortkey table (the sortkey for U+9FA5 is F0 B4 01 01 01 01 and U+F900 has F0 B5 01 01 01 01). The fact tells that it is impossible for CompareInfo/LCMapString to support higher Unicode versions, with existing Windows sortkey design. That is one of the reason that Windows can never support sorting in higher Unicode standards than version 1.0 which makes sense, as long as they keep sortkey values compatible.
Train of Sort #3 - Unicode version inconsistency
I forgot to announce that I had written an introduction to XML Schema Inference (it was nearly a month ago). I tried to describe what XML Schema Inference can do. As a technically-neutral person, I am also positive to describe what it cannot do.
I think this is also applicable to other xml structure inferences. Actually I applied it to my RelaxngInference which is however not complete. RELAX NG is rather flexible and you can add choice alternatives mostly anytime, but the resulting grammar will become sort of garbage ;-) Thus, simply-ruled structure still does make sense.
Ok, here is the third chapter of sort of crap train of sort.
Train of Sort #3 - Unicode version inconsistency
On surfing Japanese web pages, I came across aforum that there was a Japanese people in trouble that String.IndexOf() ignores U+3007 ("ideographic number zero" in "CJK symbols and punctuation") and thus his application went into infinite loop.
That code should be changed to use CompareInfo.IndexOf (s, "--", CompareOptions.Ordinal), but it seemed too difficult for those guys who posts there to understand why such infinite loop happen. That U+3007 is a number "zero" and on comparing strings "10000" and "1" are regarded as equivalent if those zeros are actually U+3007. I wonder if that is acceptable for Japanese accounting softwares.
Since there is no design contract for Windows collation, I have even no idea if it is a bug in Windows or this is Microsoft's culture (string collation is culture dependent matter and there is no definition).
When I was digging into CompareOptions, I was really mazed. At first I thought that IgnoreSymbols just indicates to omit characters whose unicode category is BlahBlahSymbol and IgnoreNonSpace indicates to omit NonSpacingMark characters. It is totally wrong assumption. Many characters were ignorable than I have expected. For example, Char.UnicodeCategory() returns "LetterNumber" for U+3007 above.
That was unfortunately before I got to know that CompareInfo() is based on LCMapString whose behavior comes from Windows 95. Since there was no Unicode 3.1 it is not likely to happen that it matches with what Char.GetUnicodeCategory() returns for each character. However, there are non-ignorable characters which are added at Unicode 2.0 and 3.0 stages (latter than Windows 95). They are still in the dark age.
Thus, there are several characters that are "ignored" in CompareInfo.Compare(): Sinhala, Tibetan, Myanmar, Etiopic, Cherokee, Ogham, Runic, Tagalog, Hanunoo, Philippine, Buhid, Tagbanwa, Khmer and Mongolian characters, and Yi syllables and more - such as Braille patterns.
There should be no reason not to be consistent with the other Unicode related stuff such as System.Text.UnicodeEncoding, System.Char.GetUnicodeCategory() and especially String.Normalize().
So, the ideal solution here would be to use Unicode 3.1 table (further ideal solution is to use the latest Unicode 4.1 for all the related stuff). So I would really like to push Microsoft to discard existing CompareInfo (leave it as is) and add collation support in an alternative class (or inside CharUnicodeInfo or whatever). Sadly it is impossible just to upgrade Unicode version used in LCMapString, keeping it compatible. It is because of some inconsistent character categories (well, anyways .NET 2.0 upgraded the source of UnicodeCategory thus GetUnicodeCategory() returns inconsistent values for some characters though) and a design failure in Windows sortkey table (I'll describle more about it maybe next time).
Train of Sort #2 - decent, native oriented
Since I have actually written nothing yesterday, this is the first body of this Train of Sort series.
I think Windows collation table is designed rather carefully than UCA DUCET. On looking into blocks (U+2580 to U+259F) I noticed that many of them have the identical primary weight (though I guess U+25EF is incorrect). Thus some of them are equivalent when you pass CompareOptions.IgnoreNonSpace to those collation methods in CompareInfo. Another example, non-JIS CJK square characters are sorted in their Alphabetical names (though I doubt U+33C3).
Similarly, Windows collation is rather native oriented than UCA. I agree with Michael Kaplan on that statement (it is written in his entry I linked yesterday).
However, it is not always successful. Windows is not always well-designed for native speakers.
What I can immediately tell is about Japanese: Windows treats Japanese vertical repetition mark (U+3021 and U+3022) as to repeat just previous one character. That is totally wrong and none of native Japanese will interpret that mark to work like that. It is used to repeat two or more characters and that depends on context. For example, "U+304B U+308F U+308B U+3022" is "kawaru-gawaru" should be equivalent to U+304B U+308F U+308B U+304C U+308F U+308B in Hiragana. It should not be U+304B U+308F U+308B U+308B U+3099. Since the behavior of those marks is unpredictable (we can't determine how many characters are repeated), it is impossible to support U+3021 and U+3022 as repetition.
Similarly some Japanese people use U+3005 to repeat more than one character (I think this might be somewhat old way or incorrect, but that repeater is anyways somewhat older one and it is notable that it is Japanese that use this character in such ways).
They are not in part of UCA and all remaining essense of Japanese sorting (like dash mark interpretation) is common. Windows is too "aggressive" to support native languages than modest Unicode Standards do.
Well, Windows is not always worse than UCA. In Unicode NFKD, U+309B (full-width voice mark) is decomposed to U+0020 U+3099. Since every Kana character that have a voice mark is decomposed to non-voiced Kana and U+3099 (combining voice mark), they can never be regarded as equivalent (since there is extraneous U+0020). Since almost all Japanese IM puts U+309B instead of U+3099 for full-width voice mark, this NFD mapping totally does not make sense with related to collation. It's just a mapping failure.
System.Xml code is not mine
I came across M.David Peterson thinking that I have written all xml code. It is quite incorrect ;-)
- System.Xml - XmlReader and XmlDocument related stuff are originally from Jason Diamond. XmlWriter related stuff are from Kral Ferch.
- System.Xml.Schema - Dwivedi, Ajay kumar wrote non-compilation part of them.
- System.Xml.Serialization - Lluis Sanchez rules.
- System.Xml.XPath - Piers Haken implemented most of our XPath engine. After that, Ben Maurer restructured the design for XSLT. XPathNavigator is Jason Diamond's work.
- System.Xml.Xsl - It is Ben Maurer who wrote most of the code.
Well, yes, I wrote most of other part than listed above (what remains ? ;-) I am just a grave keeper. And recently Andrew Skiba from Mainsoft is becoming another code hero in sys.xml area, contributing decent test framework and bugfixes in XML parsers and XSLT.
Train of Sort
The best approach to interoperability is to focus on getting widespread, conformant implementation of the XSLT 2.0 specification.
I just quoted from Microsoft's statement on XML Schema. Mhm, am so dazzled that I might have mistyped.
Actually it is quite wrong. There are some bugs in XML Schema specification e.g. undefined but significant order that happens with a combination of complex type extensions and substitution groups. None of XML schema implementation can be consistent with broken specification.
Train of Sort #1 - introduction
I have been working on our own text string collation engine that works like Windows. In other words I am working on our own System.Globalization.CompareInfo. Yesterday I posted the first working patch which is however highly unstable.
We used to use ICU for our collation engine, and currently it is disabled by default. Sadly there were some problems between our need and ICU. Basically ICU is for Unicode Collation Algorithm (UCA). Windows collation history started earlier than that of UCA, so it has its own way for string collation.
Since Windows collation is older, it has several problems that UCA does not have. Michael Kaplan, the leading Windows I18N developer (if you are interested in I18N his blog is kinda must read), once implied that Windows collation does better than UCA (he did not assert that Windows is better, so the statement is not incorrect). When I read that, I thought it sounds true. UCA - precisely, Default Unicode Collation Element Table (DUCET) - looks less related to native text collation (especially when it just depends on codepoint order in Unicode). However, on digging into Windows collation, I realized that it is not true. So here I start to describle the alternative side of Windows collation for a few days.
.NET developers want inconsistent schema validity on xml:* attributes?
Norman Walsh pointed out XInclude inconsistence against grammar definition languages. Unlike xml:id I pointed out nearly a few months ago, I believe XInclude, the new spec, is wrong here.
Why xml:* attributes should be specified in schemas you use? Because sometimes we want to restrict the value of those attributes e.g. limit "en" and "ja" in my local Japanese application. Similarly we might want to reject xml:base so that our simple stylesheet don't copy those attributes into results blindly, or processor don't read files from unexpected location. It is applications' matter.
Am disappointed at the fact that there are so many .NET developers saying that the processor should be able to accept xml:* attributes blindly. Do they want schema documents inconsistent between the processors?
I don't believe we should make XML Schema sucks just to save XInclude which is anyways borking against other schema languages.
XsltSettings.EnableDocumentFunction
This is a short followup for XslCompiledTransform. It accepts a new optional argument XsltSettings. It is an enum that holds two switches:
- EnableDocumentFunction
- EnableScript
There is a reason why document("") could be optional. When document() function receives an empty string argument, it returns a node-set that contains the stylesheet itself. That however means, XSLT engine must preserve reference to the input stylesheet document (XPathNavigator). There was a bug report to MS feedback that document() could not be resolved (I once refered to it). So this options looks like Microsoft's response to developers' need.
I thought that not keeping source document is a good idea, so I tried to remove all the references to XPathNavigator clones in our XslTransform (except for document() function). After some hacking, I wrote a simple test which assures that XslTransform does not have reference to the document:
So I tried it under Windows:
$ csc test.cs /nologo /nowarn:618 $ mono test.exe load : False transform : False $ ./test load : True transform : False
Hmm... I wonder if I missed something.
NvdlValidatingReader
Recently I put another XML validator in Mono - NvdlValidatingReader. It implements NVDL, ISO DSDL part 4 Namespace-based Validation Dispatching Language.
It is in our Commons.Xml.Relaxng.dll. I temporarily put autogenerated ndoc documents (no descriptive documents there). It will be included in the next release of Mono. For now, I haven't prepared independent archive, so get the sources from mono SVN repositry. Compiled binary should be in the latest monocharge.
Well, for those who want instant dll, you can get it from here:Commons.Xml.Relaxng.dll.
There is also a set of example code which demonstrates validation: nvdltests.zip
I'm too lazy to write something new, so here am mostly copying the description below from mcs/class/Commons.Xml.Relaxng/README.
NVDL
NvdlValidatingReader is an implementation of ISO DSDL Part 4 Namespace-based Validation Dispatching Language (NVDL). Note that the development is still ongoing, and NVDL specification itself is also still not in standard status as yet.
NOTE: It is "just started" implementation and may have limitations and problems.
By default, NvdlValidatingReader supports RELAX NG, RELAX NG Compact syntax, W3C XML Schema and built-in NVDL validations, however without "PlanAtt" support.
Usage
Using built-in RELAX NG support.
static NvdlReader.Read() method reads argument XmlReader and return NvdlRules instance.
NvdlValidatingReader is instantiated from a) XmlReader to be validated, and b) NvdlRules as validating NVDL script.
Custom validation support
NvdlConfig is here used to support "custom validation provider". In NVDL script, there could be any schema language referenced. I'll describe what validation provider is immediately later.
[*1] Of course Schematron should receive its input as XPathNavigator or IXPathNavigable, but we could still use ReadSubtree() in .NET 2.0. NvdlValidationProvider
NvdlValidationProvider
To support your own validation language, you have to design your own extension to NvdlValidationProdiver type.
Abstract NvdlValidationProvider should implement at least one of the virtual methods below:
- CreateValidatorGenerator (NvdlValidate validate, string schemaType, NvdlConfig config)
- CreateValidatorGenerator (XmlReader schema, NvdlConfig config)
Each of them returns NvdlValidatorGenerator implementation (will describe later).
The first one receives MIME type (schemaType) and "validate" NVDL element. If you don't override it, it treats only "*/*-xml" and thus creates XmlReader from either schema attribute or schema element and passes it to another CreateValidatorGenerator() overload.
If this (possibly overriden) method returns null, then this validation
provider does not support the MIME type or the schema document.
The second one is a shorthand method to handle "*/*-xml". By default it just returns null.
Most of validation providers will only have to override the second overload. Few providers such as RELAX NG Compact Syntax support will have to overide the first overload.
NvdlValidatorGenerator
Abstract NvdlValidatorGenerator.CreateValidator() method is designed to create XmlReader from input XmlReader.
For example, we have NvdlXsdValidatorGenerator class. It internally uses XmlValidatingReader which takes XmlReader as its constructor parameter.
An instance of NvdlValidatorGenerator will be created for each "validate" element in the NVDL script. When the validate element applies (for a PlanElem), it creates validator XmlReader.
XslCompiledTransform
Happy new year. (I was totally hibernating this winter ;-)
Recently Microsoft pushed another CTP version of Whidbey and I found there is a new XSLT implementation named XslCompiledTransform (BTW MSDN documentation are so obsolete that it still contains XsltCommand and XQueryCommand). It is in System.Data.SqlXml.dll, and (as long as I see Object Browser) there is no other type than XslCompiledTransform related things. (As compared to the assembly file name, it is somewhat funky.)
XslCompiledTransform looks coming from XsltCommand which is based on executable stylesheet IL code like Apache XSLTC. I wonder how many existing types such as XPathExpression and XPathNodeIterator are used in this new implementation. They might exist just for historical extension support.
I noticed that XslCompiledTransform is pretty complete. It looks a great work. I guess it would be the best improvement of System.Xml 2.0.
Here I put two important behavioral differences from existing XslTransform:
- Error recovery
According to XSLT 1.0 specification, it is an error if an attribute node is appended to an element where child elements or texts were already appended. In such cases, XslCompiledTransform throws an exception. XslTransform ignores such attributes. Both behavior are allowed in the specification.
Similarly, it is an error that if element nodes are added to an attribute as its content. Here XslCompiledTransform also rejects such output (XslTransform doesn't).
So which is better? I believe that XslCompiledTransform is. Because if you bring your stylesheet to other platform, it might be rejected as wrong stylesheet. With XslTransform, there is no way to check if your stylesheet is sane.
- Space stripping
If there is xsl:strip-space in the stylesheet, XslCompiledTransform will reject IXPathNavigable as Transform() input, saying that:
System.Xml.Xsl.XslTransformException: Whitespace cannot be stripped from input documents that have already been loaded. Provide the input document as an XmlReader instead.
The reason is, it is much easier and efficient for XSL transformation engine that those whitespaces in such elements that are listed in xsl:strip-space are originally excluded from the input document (in the transformation process, they are totally ignored). So there must be a filtering XmlReader that skips those whitespace nodes (or IXPathNavigable implementation must just do that).
If you can't change the input source from IXPathNavigable to XmlReader, you could still use new XPathNavigator.ReadSubtree() method.
Other than them, there are some minor changes (such as having Roman numbering as usual formatting, avoiding run-time prefix evaluation on "name" attributes in xsl:attribute and xsl:element), but in general, it looks good.
As for performance wise, node iterators seem to be changed as structs. That means, it does not have to worry about so extraneous object creation. I believe that it must have resulted in significant performance improvements.
So now I tend to throw away existing XslTransform and implement a new XSLTC-like transformation engine, but still not sure. With the stylesheet used in corcompare, XslCompiledTransform just resulted in only about 1.5x - 2x boost.
(2nd) Mono meeting in Tokyo
Since Duncan is coming to Tokyo this weekend, we are going to have (2nd) Mono hackers meeting in Tokyo (yes, we had the first meeting two years ago). It is planned on 19th lunch time, at Umegaoka (close to Shimokitazawa). We'd welcome a few more people who would like to in join us (sorry but a few; we have no preparation for large meeting). Please feel free to mail me (atsushi@ximian.com) if you are interested.
One of the reason why XmlSchemaValidator does not rock
After hacking label collector functionality for RELAX NG, I noticed that .NET 2.0's XmlSchemaValidator is kind of such an API (note that the link to MSDN documentation above shows so obsoleted). So I decided to implement it nearly a week ago. And now it's mostly implemented and checked in mono's svn (I think it is one of the hackiest xsd validator ;-).
Here is an example application of XmlSchemaValidator I wrote to test my implementation (it compiled with 2.0 csc).
Some of you might know that implementing XmlSchemaValidator sounds weird, because there is no API documentation for this new face (well, at least for VS 2005 October CTP which I reference). But the functionality is mostly obvious (at least to me). For example, ValidateElement() is startTagOpenDeriv, ValidateAttribute() is attDeriv, and ValidateEndOfAttribute() is startTagCloseDeriv (btw I really don't like those method names) described in James Clark's derivative algorithm for RELAX NG. One thing I was mystified was what ValidateElement(string,string,XmlSchemaInfo,string,string,string,string) overload meant, but thanks to MS developers, it was solved.
Actually XML Schema is much useless than RELAX NG stuff. XmlSchemaValidator is fully stateful, thus you cannot go back to the previous state easily. RELAX NG derivative implementation is stateless, so you can just attach those derivative instances to nodes in the editor. Oh, yes, XmlSchemaValidator could be stateful, if it supports cloning. But I don't think it can be lightweight.
btw, if you want, you can generate xsd from DTD and use XmlSchemaValidator, if you want.
rethinking element/attribute label collector
19:51 (alp) eno: dude, am never getting any expected attributes
... So, I missed the point that after RelaxngValidatingReader.Read(), my validation engine which is based on James Clark's derivative algorithm keeps the state only "after it closed the start tag" (i.e. startTagCloseDeriv in that paper) and thus no attributes must be allowed. Sigh. So, to implement attribute auto-completion, I had to expose state transition object that users can try "the state transition after an attribute occured" (i.e. attDeriv). So, now the code became more complicated than yesterday (well, it is required complexity):
I put the code example (above), and the updated result.
So now RelaxngValidatingReader implicitly expects to the validating editor not to call .Read() until it closes the start tag. Instead, now each of the elements and attributes can hold the state at the node itself. (Am not sure it really works fine; I should consider cut/paste, insertion, and so on.)
BTW, personally I don't want to expose such features and requires "implementors" of RelaxngValidatingReader functionality to implement highly derivative-dependent features like this (that is bad for standardizng API). I won't recommend to learn this feature as long-live, good to know stuff. I am, on the other hand, expecting System.Xml 2.0 to have such functionality for XML Schema (IF Microsoft people can provide), but still don't think it's worthy of standardization.
On the next stage, I will have to implement some "error recovery" stuff so that users can enter invalid nodes and the implementation can still continue remaining validation.
Many thanks to Alp to try it out with his experimental UI stuff and to let me improve this library (I could also have chance to fix bugs and to optimize Commons.Xml.Relaxng stuff).
expecting the next element/attribute names w/ RelaxngValidatingReader
(5:00am JST: Updated the API and example that looks better.)
00:18 (alp) eno: do you have any thoughts on how i could
use a DTD to hack together xml completion?
00:19 (eno) alp: you want to develop such functionality
in your app?
00:20 (eno) mhm, actually I have no idea that supports
something like nxml-mode
00:20 (alp) yeah, perhaps for monodevelop
Actually that it is sort of what I wanted. However, for DTD and XSD, the implementation is not extensible (validation implementation is hidden in System.Xml.XmlValidatingReader) So I (kinda) implemented something like that, using my RelaxngValidatingReader:
Here I put the output of the example above. It is hacky (written mostly in 2 hours) and it does not check rejection by notAllowed. It might be improved later. Also, it uses Hashtable right now, but it does not have to be dictionary.
I also added Emptiable() (of type bool) that determines if an end tag is acceptable or not in current state. Actually to complete an end element, its name should be available, but due to the difference between QName and end tag name, it should be (and could be) implemented without RELAX NG validation stuff (to support such functionality, just keep start tag names in a stack). Similarly, you should also keep track of in-scope namespace declaration to fill proper prefix that is bound to a namespace of the QName contained in the results.
Oh, BTW don't ask Alp about that "dream": he has many other tasks and interests ;-)
mcs now supports /doc
Finally, I checked in /doc support patches in mcs. I remember the first patch was written in a day, nearly 7 months ago, and that worked mostly fine.
During the hacking on it, I found some problems around /doc feature:
- There is no assurange to have documentation lines in the expected order when we are using partial types. (We can control by ordering the file names to csc.exe, but can you, especially when you use vs.net?)
- There is no check whether a documented prefix 'T:' 'F:' 'P:' 'M:' are correct.
- T:namespace_name is incorrectly allowed.
- There is no invalid comment check on (and between) attribute tokens.
- Parsing comment line looks hacky. Those '///' lines seems handled individually and thus they are laid out for each line, but when we have split markup like "/// <see\ncref='F:Foo'" it will connect those two lines, which means that the whole markup might be parsed (i.e. checked well-formedness) per line.
- "cref" attributes are pretty nasty. There is no normalization for members in the type itself (e.g. if you have TestType.FooField, there will be cref="F:TestType.FooField" and cref="F:FooField" in the resulting document).
... and more (I cannot remember anymore right now). Well, some of them are not actually problems. Some looks just bugs.
Well, actually csc must be doing better job than my hacky cref interpretation. It seems recursively tokenizing the attribute as a type name as well as the source itself, while I don't.
Anyways, it is kind of job I did only because there are some users (originally it would have been used to examine our System.Xml implementation by using NDoc in practice). I think monodoc format is much better and I don't think C# doc feature is good, as a translator who keeps track of changes in original document, usually from document themselves, not from source code files.
Now I am so glad that I can fully go back to sys.xml hackings.
RelaxngInference
Yesterday I started to write RELAX NG grammar inference. I hope this design won't **** you.
document("")
Just voted my first 5 on this very important bug that shows W3C standard conformance breakage.
Such XPathNavigator instance could be kept in memory only for such a stylesheet that contains document("")document() (it could be done in static analysis). So the reason of "by design" does not make sense.
Real developers could just implement standard-conformant implementation in easy way, instead of using casuistry on whether it is conformant or not, which just result in imposing annoyance on real users.
Let's make System.Xml 2.0 not suck
On the suggestion on "infer elements always globally", Am getting positive feeling from Microsoft XML guys via the feedback center.
On the other hand, am getting negative response for the suggestion on XmlSchemaSimpleType.ParseValue() which validates string considering facets. But I believe that XML Schema based developers will be absolutely appreciated by that feature. For example, it will be mandatory for XQP project that must support user-defined type constructor defined in the section 5 of W3C XQuery Functions and Operators specification. Microsoft guys might want to help your development.
It depends on you, XML developers, whether Microsoft will improve their library or not. We could provide our own advantages, but it would be still better that your advanced code will run on MS.NET too.
(FYI: You can "vote" for the suggestions ;-)
Useful codeblock
I've 90% finished XmlSchemaInference. I implemented it only because .NET 2.0 contains it.
XmlSchemaInference is very useful. For example, if you have such document like:
It creates two different definition of "product" elements. Here is the infered schema and generated serializable class.
So now I wonder if I had better port the same feature to Commons.Xml.Relaxng. RELAX NG is not so sucky than XML Schema, so I might be able to provide better XML structure inference engine. But XML structure inference itself is not so fun.
... after some thoughts, I decided to enter a new suggestion to MS feedback center which seems working again recently.
xml:id and canonical XML
I found that the Last Call working draft of xml:id was out. But I think xml:id will be incompatible with Canonical XML (xml-c14n). Below is an excerpt from 2.4 Document Subsets in xml-c14n W3C REC:
The processing of an element node E MUST be modified slightly when an XPath node-set is given as input and the element's parent is omitted from the node-set. The method for processing the attribute axis of an element E in the node-set is enhanced. All element nodes along E's ancestor axis are examined for nearest occurrences of attributes in the xml namespace, such as xml:lang and xml:space (whether or not they are in the node-set). From this list of attributes, remove any that are in E's attribute axis (whether or not they are in the node-set). Then, lexicographically merge this attribute list with the nodes of E's attribute axis that are in the node-set. The result of visiting the attribute axis is computed by processing the attribute nodes in this merged attribute list.
Well, I don't think xml:id is wrong here. It is xml-c14n that is based on non-committed premises that all xml:* attributes must be inherited (yes, xml:lang, xml:space and xml:base were). Anyways, don't worry about that incompatibility. Canonical XML is already incompatible with XML Infoset with related to namespace information items.
A change of seasons

Many of my friends have been saying that they feel sorry for Rupert that he does not have any more clothes in this cold season. Today I was hanging around Shibuya (central Tokyo area) with my friends, and they were so kind to buy a new one for him (from my budget). Now he looks younger than before.
XmlSchemaInference
I was escaping from /doc stuff and looking into xsd inference task (I cannot stand working only on that annoying task). I wrote some notes but incomplete. Apparently the most difficult area is particle inference, but right now not so many ideas. My current idea is to support non-XmlSchema language.
the latest /doc patch
I've finally hacked all /doc support feature, including the related warnings. Am now working on testing stuff; I've already done warning tests, but need to compare results. Here's the latest patch and the set of the compiler sources.
monodoc-aspx on windows
For those who are interested, here is my local changes in monodoc to make monodoc-aspx runnable on windows.
ResolveEntity()
XmlReader.ResolveEntity() is one of the biggest problem for custom XmlReader implementors, since it never provides XmlParserContext. Well, most of those implementations would just use XmlReader as construction arguments. In such cases, they could just invoke the argument XmlReader's. ResolveEntity(). If you have DTD information (name / public ID / system ID/internal subset), then you're still lucky; because you can create XmlDocumentType node and XmlEntityReference that holds ChildNodes. That's how our XmlNodeReader is implemented now.
btw, XmlTextReader in System.Xml 2.0 can resolve entities. It means, now XmlTextReader always checks if there is entity reader inside the class. Actually the similar situation lies in XmlNodeReader and DTD validating reader. They are mostly the same (still different though). As an example, I wrote new XmlNodeReader and XmlTextReader based on the old implementations, but on entity handling, they are so close. So I think, handling entity-resolvable XmlReader might be possible to extract to one (abstract) class - I haven't tried though (since I cannot change the class hierarchy on XmlNodeReader and that of XmlTextReader).
A similar problem and possible solution lies under post validation information providor (such as DTD validator and XSD validator, that handle default values). But I won't provide common solution for it, because people should never use something like PSVI that makes documents inconsistent (well, entity is also, but it is already-happened disaster).
The United States of Absurdity
Am being disappointed in American citizens.
Anyways, XmlTextReader got 20% faster yesterday in my box and in my testing. With my pending patch, it even goes 33% (as total), but I haven't committed as yet because it is nasty, expanding some functions inline manually.
XQueryCommand is dropped. How about XQueryConvert?
From the revision log of latest W3C XQuery 1.0 working draft:
A value of type xs:QName is now defined to consist of a "triple": a namespace prefix, a namespace URI, and a local name. Including the prefix as part of the QName value makes it possible to cast any QName into a string when needed.
xs:QName is mapped to XmlQualifiedName, which only contains local name and namespace URI.
CS1587
I decided to postpone /doc patch checkin (well, requesting approval and checkin) for a while (maybe two weeks or so), since there are many dangerous factors (many changes and breakage) for committing patches right now. Instead, I decided to create the complete patch for /doc (that implies no more significant changes intended).
But that also means, I have to add parser/tokenizer annoyance for CS1587 "XML comment is placed on an invalid language element which can not accept it." ... it is really annoying. Just for the support for that warning, my small patch increased 1.5 times larger than before. And since doc comment is not kind of token which can be recognized by the parser (it is not "error" to have those comments in improper code blocks), the task is mostly done by the tokenizer, and I need to keep track of token transition at a time. Having tokenization control code both in parser and in tokenizer is a bad idea, but there was no better way (there was a similar annoyance in XQuery parser).
Anyways, that CS1587 task is mostly done (I hope so). I still have to handle 'cref' related warnings, which are also annoyance.
It is still a mystery that such person that dislikes /doc feature is working on it (ah, but was ditto for XmlSchema ;-).
[19:30] I noticed that I had been making significant changes with related to the latest changes in mcs that makes my /doc patch mostly useless. Here's the latest patch.
Japanese Monkeyguide Translation
Recently one Japanese person has been contributing monkeyguide translations (well, we know that monkeyguide is old). I put those translations here. Those it is rather a repositry than good-to-browse pages. The files are still raw (because old monkeyguide did not have index.html).
Some Japanese people complains that there is no Japanese resources. We have. Please navigate from http://www.mono-project.com to "Resources" >> "Related Sites" >> "Mono Japanese Translation". The page style is old, but the large part of the translations are up-to-date (well, the web pages are slightly changed after the 1.0 release).
On upcoming System.Xml 2.0 changes
Improved mcs /doc support patch
I had left my /doc patch as broken for a cpl months. But since there are many voices of need, I decided to fix and improve it. Here is the latest patch am working on. I'll post it when I finished remaining warning stuff (thanks again to Marek for the list).
On upcoming System.Xml 2.0 changes
http://blogs.msdn.com/DareObasanjo/archive/2004/10/13/241591.aspx
In short, it is nice.
So now XQuery is being removed. No wonder. Apparently, XQuery won't become W3C REC until .NET 2.0 gets out. It is a good decision that Microsoft dropped XQuery from their forthcoming .NET FX, despite being regarded as "now XML 2.0 is not so fantastic". But just imagine; we know how MSXML brought confusion wrt http://www.w3.org/TR/WD-xsl, and we - well, at least I - don't want another disaster.
Actually besides the progress of the spec, even with the latest working draft, there are some difficulty on current .NET XQuery implementation strategy that premises the unity of CLR and XQuery datatypes. For example, with xs:gYearMonth mapped to System.DateTime, you can't implement XQuery 1.0 and XPath 2.0 Functions and Operators section 17. Casting. It also applies to conversion between xs:QName and xs:NOTATION (both are represented as XmlQualifiedName, while those types differ in casting to xs:string and xdt:untypedAtomic (it can be avoided by making derived class for xs:NOTATION though).
Other than XQuery, there seems some nice improvements. For example, XPathDocument is no longer editable (it makes sense very much), XmlReader.Create() supports XmlParserContext (maybe like I thought that we need something like IXmlParserContext), and so on. Am especially interested in XmlSchemaValidator that might help people creating validating XML editor. I have no idea what it is like, but it sounds cool.
Oh, BTW it does not mean that our XQuery implementation will be totally discarded. Well, it will disappear from System.Xml.dll (and less important but from System.Data.SqlXml.dll too), but it might be extracted into another library. ATM, it cannot handle positional predicates, sequence type matchings, many XQuery functions, and more, but it can already handle some of the queries from XQuery Use Cases (you will need some special XmlResolver to handle those nonexisting document instances though).
Leaving Japan for a while
Am going to Cambridge and attend to XMLOpen 2004, to learn English^W the latest XML technologies. After that, vacations :-) Am looking forward to my first visit to Europe. Will be in London, Brussels (currently a dinner with Gert is planned), and Heidelberg. I'll appear again on 1st Oct, in Ximian office, and will spend most of that month there.
new Microeconomics by Krugman/Wells
I found that the forthcoming Microeconomics book by Paul Krugman and Robin Wells contains a sample chapter on Technology, Information Goods and Network Externalities [pdf], refering to CTEA. Nothing should be new to Lessig readers though.
XPathDocument Changes
As a sincere ex-law student the worst thing I dislike is false advertisement and unfair trade. And now am spending my time on persuading people saying that copyright is a natural right (sigh). I wonder if I should directly tell the fact that the origin of exclusive right had started just from British book companies.
I put my translation of Miguel's Longhorn Changes into Japanese. You can read it from here. There are no or few people who share the ideas for that matter with Miguel in Japan, so this translation should be informative for Japanese developers.
I had been saying that developers won't use XPathNavigator. I don't have any statistics, but it was obvious, like Avalon and XP. Actually, as a developer who had spent much time on debugging XSLT that is based on XPathNavigator rather than DOM, I don't believe that XPathNavigator is better for practical development, while don't deny that XPathNavigator is cool.
It is a while ago, but there were announcement on System.Xml.XPathDocument being reverted. No wonder, and no need to be afraid. XPathEditableNavigaor is said as still remaining. Only XPathDocument is eliminated. The voices saying that "XPathDocument rocked!!" are really ignorable. XPathEditableNavigator is much easier than XPathDocument because it doesn't have to support transaction (AcceptChanges() and RejectChanges()). XPathEditableNavigator can be implemented over XmlDocument.
(I have no idea how XPathEditableNavigator will be provided though.)
To my feelings, to be IRevertibleChangeTracking, XPathDocument must have been like XmlDocument that might contain sequential text nodes, otherwise it must had too-complex internal change states. It was too unnatural for XPathDocument which is so close to XmlDocument to be able to be much faster. There should be actually little performance difference between XPathDocument and XmlDocument (MS XPathDocument must be based on tree node model unlike our DTMXPathNavigator which is based on document table model).
Some guys say that XmlDocument is 10x or more slower than XPathDocument. It is totally not practical. To my knowledge, it only applies to some kind of reverse-axis queries such as preceding-sibling::*. It is because XmlNode does not have reference to PreviousSibling. If XmlNode is going to have such reference, then its performance should not be different from XPathDocument. Since now that Microsoft XML team publicly said that they will improve XmlDocument, they could make such changes.
Editable XPathNavigator from XPathDocument is still annoyance for such people like me who found that read-only document structure is faster than editable one (I was being forced to implement slower XPathNavigator just for such a silly change). But I won't care. Our internal use of XPathNavigator will be still faster DTMXPathNavigator.
There were another degrading discussion saying that XmlDocument's SelectNodes() will suck with XmlNamespaceManager. That is really not true. Now SelectNodes() should be able to accept IXmlNamespaceResolver like XPathDocument (XmlDocument will be improved, no?) and thus they could write like "theNode.SelectNodes(xpath_string, new XmlNodeReader (theNode))". Or even XmlNode could implement IXmlNamespaceResolver (there are already similar methods like GetPrefixOfNamespace()).
Wondering around CLI function support for XQuery
Am on designing something like CLI native function call support in our XQuery engine. Right now the code below runs with our cvs version.
(sorry for those who disables JavaScript - '<' is incorrectly escaped.)
The original idea is from SAXON 8.0 that supports Java method invokation (and yes, it also looks like IXsltContextFunction). Currently my implementation immediately infers every external functions as native public static methods, and I don't like this design (especially "everything is CLI method" design, and the point that we must define every functions. It could be easy module imports).
I wonder how Microsoft developers think about XQuery extensions.
The truth on RELAX NG, XML Schema and XML serialization
In short, there is no reason you cannot use RELAX NG in your web services theoretically. That's just the matter of insufficient implementation support of frameworks rather than spec matter.
As I implemented RelaxngDatatypeProvider in Commons.Xml.Relaxng.dll that supports XML Schema datatypes, you can use RELAX NG to represent "typed grammar". And it is possible for some grammars to map its items to runtime types (it is "theoretically" impossible to support runtime-type mapping for all kind of RELAX NG grammars. Read more for details). On the other hand: XML Schema is (also) not always mappable to runtime types. You can try xsd.exe with this simple example schema below and what useful classes it generates:
(I haven't checked how JAXB 1.0 RI works here.)
The fact is: if you are lucky, your schema can be used for object mapping.
For RELAX NG side, we don't have runtime type mapping tool yet. At least, target grammar must be "deterministic" which is one of the reason why XML Schema is much complex than RELAX NG (XML Schema forces deterministic schema, while RELAX NG allows non-deterministic grammars). To implement it, first we have to create non-deterministic grammar detection utility (like RelaxMeter by Kohsuke Kawaguchi, which is, however, to detect ambiguity).
Once deterministic grammar detection got implemented, we can implement object mapping using RelaxngDatatypeProvider noted above.
But note that, for usual develoers, understanding "how we can create deterministic grammar" might be more difficult than understanding and believing XML Schema blindly (actually it won't be, since XML Schema has some extraneous buggy things like substitution groups). In fact am one of such people who don't fully understand how deterministic model detection will work on RELAX NG.
Am not interested in other discussion such like "New X won't be your solution, since every existing systems are based on old Y". We're those people who believed that .NET Framework makes development easier, while it had abandoned legacy stuff.
Hello, XQuery
I've been apart from cvs log history for a while, because I was XQuery pregnant.
_@r50 ~/tests/xml2_0/xquery $ csc hello.cs -r:System.Data.SqlXml.dll -nologo _@r50 ~/tests/xml2_0/xquery $ ./hello <doc>hello, XQuery.</doc> _@r50 ~/tests/xml2_0/xquery $ mono hello.exe <doc>hello, XQuery.</doc>
Not sure when I can leave this hospital.
NemerleCodeProvider
Today was the first day I tried to touch Nemerle. Inspired by Miguel's post, I created NemerleCodeProvider. There must be many mistakes caused by my ignorant of nemerle specification, but right now it would do something.
Since our xsd.exe can load external code provider, I tried my provider with xsd.exe.
[*1] test.n
[*2] test.n
The former test.n compiles, but curiously the latter one didn't compile. Today I have no clue (I tried to talk to nemerle community but could not get connected).
XPathDocument2Editable
Yesterday I put XPathDocument2, saying that it could be easily made as editable. And (against my expectation) today I made another XML toy. Well, am mostly functioning just as a copy machine of (my) prior ones.
It is one day hacking, based on XPathEditableDocument I put last Thursday.
wandering around XPathDocument2
After making XmlDocumentNavigator editable, today I was trying to create another XPathDocument based on another tree model like XOM... that will be editable in a few days (on the same way as shown in XmlDocumentEditableNavigator), but I hoped too much for today's XML toy. In fact the basic tree model is created nearly a week ago, so today I just added Load() and XPathNavigator implementation (though I had to modify the large part of the tree model). Right now it just implements IXPathNavigable (it won't be difficult though), and has some limitation (e.g. MoveToId() won't work right now).
In fact, at first I intended to create more useful document API like XOM for new XPathDocument, but I found that new XPathDocument had better be more simple implementation that is not kind for "users" (such like omitting parameter checks). Thus, the tree model now became so different from original XOM way. Like MS one, this XPathNavigator is "a bit" faster than XmlDocumentNavigator, but it is not faster than our DTMXPathNavigator. I just tried only those navigation API used in XPathNavigatorReader, so on reverse axes it will be much faster than XmlDocumentNavigator. This code is just two days' hack, so it might have many bugs. Well, yesterday's XPathNavigatorReader was so buggy and I've fixed many bugs in cvs.
sorry, today's toys are not so interesting ones
I've checked today's toy in cvs; SubtreeXmlReader.cs. It is used to implement XmlReader.ReadSubtree().
After creating it, I felt sorry, since it is not interesting one. So today I made another subtree reader; XPathNavigatorReader.cs (for XPathNavigator.ReadSubtree()). It in fact used to be in cvs for a while (and moreover I made it more than 1 year ago), but it did not behave as a fragment reader.
Well, though they are based on 2.0 bits, they could be easily modified to be usable on 1.x. Once such modification is done, you could replace XmlReader.ReadSubtree() and XPathNavigator.ReadSubtree() with them for backward compatibility. They are also runnable under MS.NET.
Update [7/31]: The XPathNavigatorReader implementation was so buggy... so please pick the correct implementation up from mono cvs.
Who said that XmlDocument's XPathNavigator is not editable?
On implementing XML 2.0 bits, I noticed that I need something new in our implementation - such as subtree XmlReader from XmlReader, or XPathNavigator fragment reader. So there seems many interesting toys I have to implement.
In Microsoft's .NET Framerowk 2.0, XPathNavigator that is created from XmlNode is not derived from XPathEditableNavigator. It is not cool, since DOM is editable. So here I hacked a new toy named XPathEditableDocument that implements IXPathEditable and created from XmlDocument. Right now I just tried only a few members.
It can be used like:
... and that XPathEditableNavigator can be (maybe ;-) used as usual. It is also runnable under MS.NET 2.0. This code contains a short testing driver, so comment them out before using it.
Am not sure if I am going to implement (well, test enough) other interfaces implemented in XPathDocument (such as IRevertibleChangeTracking), but it would be usable to implement some XPathEditableNavigator dependent part in XQuery implementation (well, it doesn't have to be dependent on that class though).
I also think that we can adapt this class in our XmlNode.CreateNavigator(). I There is little worry about breaking existing stable implementation. In this code, XmlDocumentEditableNavigator is mostly just wrapping internal XmlDocumentNavigator (mono's DocumentXPathNavigator). Of course, it can be supported only post-1.0.
I would like to recommend Microsoft XML guys to make XmlDocument as IXPathEditable like this way. It will make XPathEditableNavigator more stable (having two implementations is much better than having just one implementation, especially there are virtual members that is overridable by third parties). It doesn't have to be as complex as XPathDocument, by omitting some interfaces such as transaction support.
how to disappear completely
The day before yesterday, I wrote that XQuery 1.0 SchemaContextLoc will become obsolete soon. The same day W3C announced another new XQuery WD, which completely removed SchemaContextLoc from ValidateExpr. Wow. Am glad to know that and no sooner I did eliminate SchemaContext from my parser stuff (in my box yet). Such a niche functionality should be done by extensions, not by standard. Now everything in its right place.
2,000,000 of listeners who had spent $1,000 in 5 years moved from commercial records to Winny
Hmm, my last entry went under 7/25. So I wanted to insert noise here.
ACCS is kind of BSA in Japan. They reported that commercial records decreased $40,000,000 of sales in those 5 years, and it is because of Winny, a file sharing tool (that did not exist 5 years ago). They also said that there are 2,000,000 Winny users. Thus, at least every users had spent $1,000 in 5 years must have ceased to buy commercial records because of Winny. Wow!
It describes how reliable their staticsics are. If you found any literatures that reference their statistics, you had better advise them to find another ones. You can also rank such literatures by yourself.
Similarly, if any of you know any associates or statistics (latter would be preferable) in your country that are unreliable, please tell me. I decided to create a black list (mainly) for Japanese IP researchers.
Looking forward to XQuery 1.1
Today I checked in my first XQuery parser stuff, with some hack on System.Xml.Query.XQueryCommand (in System.Data.SqlXml.dll). DISCLAIMER: It won't do anything other than parse ;-) I tried all the query examples contained in XQuery Use Cases, though it is still incomplete. Besides "fn:empty" function call, only 3 examples fail (The reason why fn:empty fails is like what this message appeals - empty() and empty(item) are still? ambiguous to my parser). I put those extracted examples here.
The next stage is to design static context model from current abstract syntax tree. And it will be concurrently done with kinda XPathItemIterator design. Other new XML 2.0 API might be implemented when I want to run away from XQuery I want to use them in XQuery implementation and/or I want to fill missing bits, as I have done in this month.
BTW, recently W3C published the updated working draft of XML Schema component designator. If you know XQuery, you will notice that the spec targets exactly as the same one as the terminal named SchemaContextLoc in XQuery 1.0. To me, it looks like the near future version of XQuery 1.x will replace that SchemaContextLoc part and XQuery 1.0 might soon get obsolete like http://www.w3.org/TR/WD-xsl in a few years (unless that Component Designator spec gets discarded).
Of course, that does not mean "it is no worth learning XQuery after publication of 1.0 spec". XQuery might be one of the most useful XML processing language. It just means that "some" schema-related part of XQuery would become obsolete. It is also true to XPath 2.0 and thus XSLT 2.0.
One possibility is that the component designator spec work soon gets W3C recommendation status, and XQuery 1.0 uses that spec. That would be nice, but early implementation of XQuery will be still unstable then.
on MS Compatibility or W3C Conformance
My recent flamatory on MS/W3C conflict went to xml.com article (yes, what I wanted is not only talking about XmlTextReader). No sooner I got response from Dare Obasanjo (Microsoft XML PM) via Miguel. And I found the Microsoft feedback page is enough cool to view others' bug reports. I filed that matter, but no sooner I got quicker reply from the development team from Dare. I believe Miguel is on the right way and I'd like to be cool as he drew. I'd expect that MS guys would have taken (or would take) the same way on SAX.NET project they had commented.
Oh, BTW I am not a "W3C God" believer (as shown in the excerpt in xml.com or even on Dare's weblog; I had been afraid of being said as such). People should note that it is also ECMA CLI specification. (No need to worry about XmlCDataSection; XmlDocument is not part of ECMA CLI).
Anyways that bug won't be fixed under MS.NET because (as Dare posted to the mono-devel-list; well, its maybe waiting for approval) Microsoft customers might have already been dependent on this bug (as Ian already shown). So I'll fix by providing MS compatibility mode or Mono improved mode - yes, finally none of W3C standard conformance situation was solved here.
documentation patch delayed
Roughly three months ago I wrote /doc support patch for mcs. For several reason, it is still not in cvs. The patch is not a small one, so we could not incorporate the patch before mono 1.0 release. I had no trouble keeping the patch in my working mcs for those months, bug we didn't want to add unstability. After 1.0, Miguel asked me to check the patch into cvs. So I posted the patch to the list (recent one). Sadly to say, the next day it broke strongname signing. I could not find where the problem lay, and it got working one day later. So I decided not to check in now and wait for a while.
I started .NET 2.0 XML tasks. It is my primary task until 1.2 release.
Tanabata
Pablo (tetsuo) asked that why am not blogging. Well, I am ;-) but haven't posted for a while. Now am switching to lameblog.
I want to write about some lightweight tasks that is however a bit important. These cpl months we had to fix core individual classes such as System.Decimal that needed fixes. I also touched a few classes such as System.DateTime and System.Uri mostly for the first time. I felt that those classes can be rewritten for performance and v2.0 compatibility. I didn't such optimization since it needs more time than we could spend, and it's not time to make them unstable.
- In System.DateTime, there are many Substring() (mostly Substring (1)) that internally creates many string instances.
- More or less ditto for System.Uri. System.Uri design can be more rational. In v2.0 we also have to handle relative URI construction.
I just put two examples, but there should be more.
Mono (still) also have not a little tasks to do. For example, our CultureInfo is not complete. That is mostly culture-specific matter, but there are more general problems, such as DateTime above and Calendar integration (how DateTime.Parse() should work against calendar-specific day and month names; how calendar-specific DayNames should be checked against different year/month/day count such in ThaiBuddhistCalendar (here I wish there were hackers from Thailand ;-).
If any of you want to help, please let us know.
Yesterday was "tanabata" in Japan; People wrote their wishes on cards and put them on bamboo. Rupert also did:
